What is Memory Alignment?
In computers, memory space is divided by bytes. Theoretically, it seems that access to any type of variable can start from any address. However, in reality, when accessing specific types of variables, they are usually accessed at specific memory addresses. This requires restrictions on the storage locations of these data in memory. Various types of data are arranged in space according to certain rules rather than sequentially one after another. This is alignment.
Memory alignment is within the jurisdiction of the compiler. It manifests as: the compiler arranges each “data unit” in the program at an appropriate position.
Why Memory Alignment?
To explain this problem, we first need to understand how the processor reads memory.
If we regard memory as a simple array of bytes, for example, in C language, char * can represent a block of memory. Then we might think that its memory reading method can read sequentially by 1 byte, as shown in the following figure.
However, although memory is in bytes, most processors do not access memory in byte blocks. It depends on the data type and processor settings; it usually accesses memory in blocks of 2 bytes, 4 bytes, 8 bytes, 16 bytes, or even 32 bytes. We call these access units the memory access granularity.
Now we know that the computer’s processor reads in blocks of a certain size, which is our prerequisite. Then, to explain why memory alignment is needed, let’s first look at what problems will occur in the case of misalignment.
Alignment is related to the position of data in memory. A variable is said to be naturally aligned if its memory address is exactly an integer multiple of its own length. For example, an integer variable (occupying 4 bytes) with an address of 0x00000016 is naturally aligned.
Now assume that an integer variable (4 bytes) is not naturally aligned, and its starting address is at 0x00000002 (blue area in the figure). When the processor wants to access its value, it reads according to a 4-byte block, starting from 0x0 in the figure and reading 4 bytes to 0x3.
After this reading, we cannot get the integer data we want to access. Then the processor will continue to read downwards, offset by 4 bytes, starting from 0x4 and reading to 0x7.
At this point, the processor can read the memory data we need to access, and of course, there is a process of elimination and merging in between.
So, in this example, when the starting address of the integer variable is at 0x2 (misaligned), the processor needs two reads to get the content we want to access.
What if it is aligned?
Obviously, if it is aligned, in this example, we can read the target data with only one read.
It can be seen that alignment affects reading efficiency.
At the same time, various hardware platforms handle storage space very differently. Some platforms can only access certain types of data from certain specific addresses, not any address in memory. For example, the CPU of some architectures will have errors when accessing an unaligned variable. So programming on such architectures must ensure byte alignment. Other platforms may not have this situation, but the most common thing is that if the data storage is not aligned according to the requirements of their platform, it will cause a loss in access efficiency. It is also because data can only be read at specific addresses that when accessing some data, for accessing unaligned memory, the processor may need multiple accesses; while for aligned memory, only one access is needed.
This is why memory alignment is needed. Memory alignment not only facilitates fast access by the CPU but also reasonable use of byte alignment can effectively save storage space. We can also compare the different impacts of different memory access granularities on the same task. Set the same task: read 4 bytes from address 0 from Address0 and Address1 into the processor’s register respectively.
First, let’s look at the case of single-byte granularity
In the two figures, the left side represents memory, the right side represents registers, and the arrow in the middle represents the reading process. Because it is single-byte access granularity, memory is accessed by 1 byte. So for Address0, to read 4 bytes from position 0, 4 reads are needed, and the same for Address1. It doesn’t matter even if it is not memory-aligned.
Then look at the case of double-byte granularity
Reading 4 bytes from Address0, compared with a processor with 1-byte access granularity, the number of accesses is halved, requiring only 2 reads. Since each memory access has a fixed overhead, minimizing the number of accesses can indeed improve performance. At the same time, Address0 is memory-aligned (the starting position of the data falls at position 0), so the first read of address 0-1 and the second read of address 2-3 can get the target data.
However, when reading from Address1. Because the address does not fall evenly on the processor’s memory access boundary (the black frame area of the register in Address1 is the memory address area of the data, starting at position 1, which is not aligned), when the processor fetches data, it must first read the first 2-byte block (0-1) starting from address 0, eliminate the unwanted byte (address 0), then read the next 2-byte block (2-3) starting from address 2, and then read the next 2-byte block (4-5) starting from address 4, and eliminate the unwanted byte (address 5). After reading 3 times, the remaining 3 blocks of data are merged into the register to get the target data.
What about 4-byte granularity?
A processor with 4-byte granularity can read 4 bytes from the aligned address by reading address 0-3 once when reading from Address0.
However, when reading from Address1, because it is misaligned, read address 0-3, eliminate address 0, then read address 4-7, eliminate address 5, address 6, and address 7. After reading twice, merge the remaining 2 blocks of data into the register to get the target data.
It can be seen from double-byte granularity and 4-byte granularity that for unaligned memory, more reads, eliminations, and merges are needed. This obviously reduces efficiency.
We also need to note that for aligned memory, different access granularities also affect access efficiency. Smaller granularity means more accesses, and larger granularity means wasted space. So compilers on each specific platform have their default access granularity.
After understanding memory alignment and its reasons, let’s continue to look at the principles of memory alignment.
Memory Alignment Rules
- For standard data types: its address only needs to be an integer multiple of its length.
- For structures: in a structure, the compiler allocates space for each member of the structure according to its natural boundary (alignment). Each member is stored sequentially in memory in the order they are declared, and the address of the first member is the same as the address of the entire structure. The specific rules are as follows:
- The first member is at the address with an offset of 0 in the structure variable, that is, the first member must start from the beginning.
- Each subsequent member’s offset relative to the start address of the structure is an integer multiple of the size of that member. If necessary, the compiler will add padding bytes between members.
- The total size of the structure is an integer multiple of the maximum alignment number (each member variable has its own alignment number). If necessary, the compiler will add padding bytes after the last member.
- If a structure is nested, the nested structure is aligned to an integer multiple of its own maximum alignment number, and the overall size of the structure is an integer multiple of all maximum alignment numbers (including the alignment number of the nested structure).
Let’s take an example:
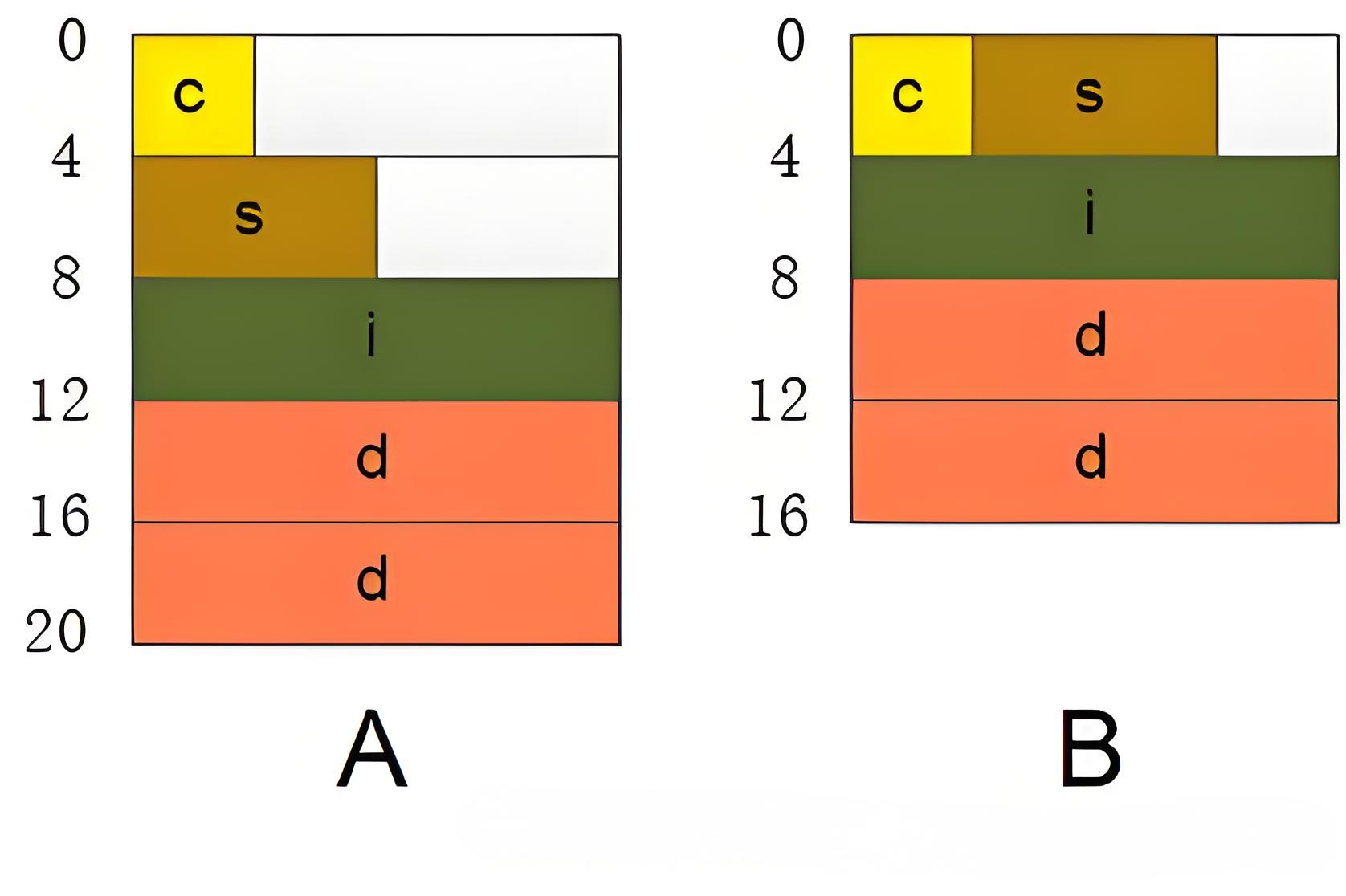
struct test_t {
int a;
long b;
short c;
};- The first member is of type int, occupying 4 bytes, and the memory distribution is 00 01 02 03, represented in red.
- The second member is of type long, occupying 8 bytes. At this time, the offset 04 of the memory is not an integer multiple of 8, so padding bytes (represented in green) are added to position 0x7, and then the long type data b is written into the memory (yellow).
- The third member is of type short, occupying 2 bytes. At this time, the offset 16 of the memory is an integer multiple of the number of bytes occupied by the short type, so it is directly written into the memory (represented in blue).
So far, the data members in the structure have been aligned, but the total size of the current structure is 18, which does not meet rule 3. So 6 bytes need to be filled after the last member to make the total size 24.
If we swap the short type and long type in the structure:
struct test_t {
int a;
short b;
long c;
};The result is 16. It can be seen that for structures with the same members, changing the order of members will affect the size of the structure’s space. Therefore, we not only need to understand memory alignment but also use memory alignment correctly.
For structures nested within structures, it has been given in rule 4, and the figure here will not be drawn again. Smart as you are, after seeing this, you must be able to get the correct answer.
- The starting address where each member variable is stored, the offset relative to the starting address of the structure, must be a multiple of the number of bytes occupied by the type of the variable.
- Each member variable applies for space in the order they appear in the structure when stored, and adjusts the position according to the above alignment method. The vacant bytes are automatically filled.
- To ensure that the size of the structure is a multiple of the byte boundary of the structure (that is, the number of bytes of the type that occupies the largest space in the structure), after applying for space for the last member variable, the vacant bytes will be automatically filled as needed.