1. What is MVCC?
MVCC (Multi-Version Concurrency Control) is a method of concurrency control. Generally, in database management systems, it realizes concurrent access to databases.
2. How does MySQL implement MVCC?
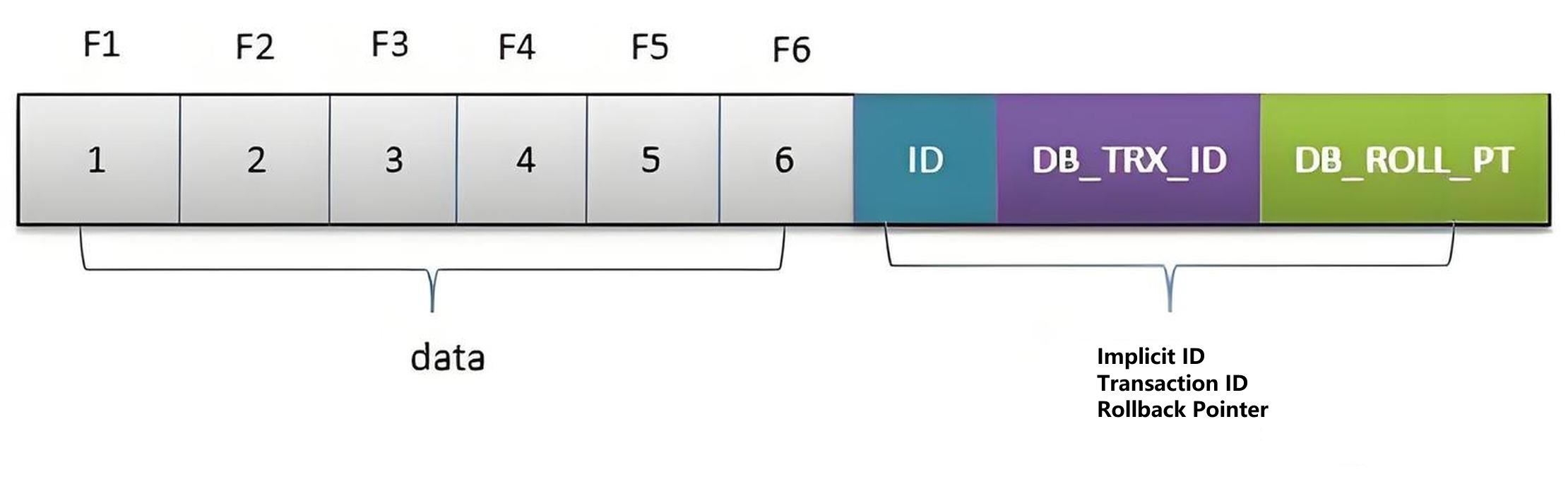
The most basic row stored in InnoDB contains some additional storage information: DATA_TRX_ID, DATA_ROLL_PTR, DB_ROW_ID, and DELETE BIT.
- DATA_TRX_ID marks the transaction id of the latest update to this row of records. Each time a transaction is processed, its value automatically increases by 1.
- DATA_ROLL_PTR points to the undo log record of the rollback segment of the current record item. It is through this pointer that previous versions of data are found.
- DB_ROW_ID: When InnoDB automatically generates a clustered index, the clustered index includes the value of this DB_ROW_ID; otherwise, it does not. This is used in indexes.
- The DELETE BIT is used to identify whether the record has been deleted. Here, it is not a real deletion of data, but a marked deletion. The real deletion occurs when committing.
2.1 Initial insertion of data rows
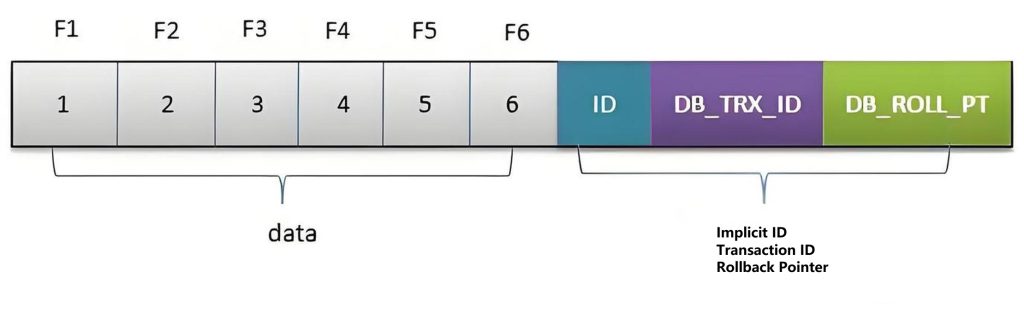
F1 to F6 are the names of certain columns, and 1 to 6 are their corresponding data. The last three implicit fields correspond to the transaction number and rollback pointer of the row. If this data is just inserted, it can be considered that the ID is 1, and the other two fields are empty.
2.2 Transaction 1 changes the values of each field in the row
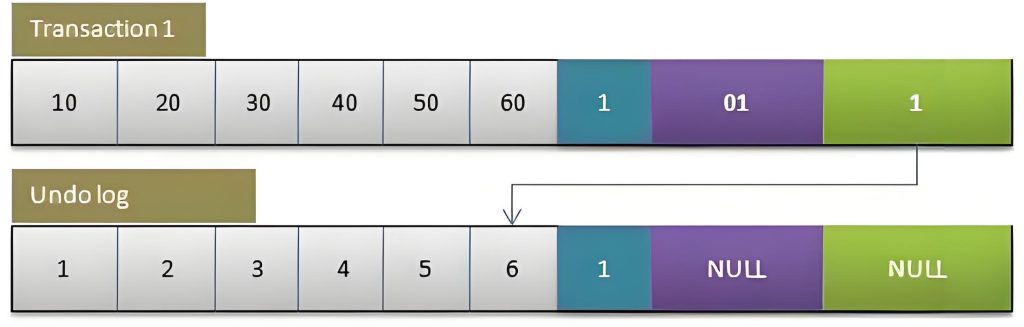
When transaction 1 changes the value of the row, the following operations will be performed:
- Lock the row with an exclusive lock.
- Record the redo log.
- Copy the value of the row before modification to the undo log, which is the row below in the figure.
- Modify the value of the current row, fill in the transaction number, and make the rollback pointer point to the row before modification in the undo log.
2.3 Transaction 2 modifies the value of the row
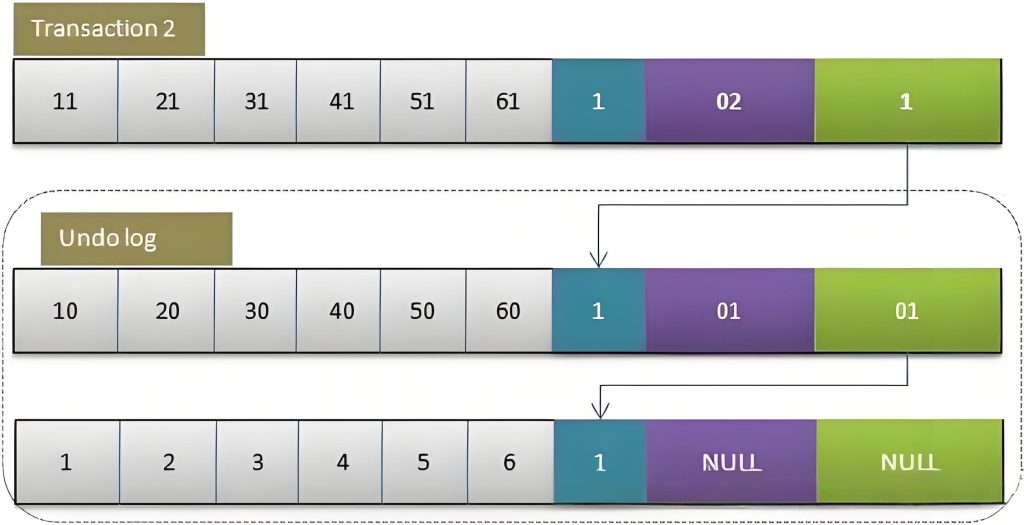
Similar to transaction 1, at this time, there are two rows of records in the undo log, which are connected through the rollback pointer. Therefore, if the undo log is not deleted, the initial content of the row when it was created can be traced back through the rollback pointer of the current record. Fortunately, there is a purge thread in InnoDB, which will query the undo logs that are older than the oldest active transaction and delete them, so as to ensure that the undo log file does not grow infinitely.
When a transaction is normally committed, it only needs to change the transaction status to COMMIT, and no other additional work is required. However, Rollback is slightly more complicated. It needs to find the version of the transaction before modification from the undo log according to the current rollback pointer and restore it. If the transaction affects a large number of rows, the rollback may become inefficient. According to experience, when the number of rows in a transaction is between 1000 and 10000, the efficiency of InnoDB is still very high. Obviously, InnoDB is a storage engine with higher COMMIT efficiency than Rollback.
3. What are the particularities of InnoDB’s implementation of MVCC?
The above-mentioned establishment of undo log before update and non-blocking reading according to various strategies is MVCC. The rows in the undo log are the multiple versions in MVCC, which may be quite different from our understanding of MVCC. Generally, we think MVCC has the following characteristics:
- Each row of data has a version, and each data update updates this version.
- When modifying, copy the current version for arbitrary modification, and there is no interference between transactions.
- When saving, compare the version numbers. If successful, commit and overwrite the original record; if failed, discard the copy (rollback).
That is, each row has a version number, and the success of saving is determined according to the version number, which sounds like an optimistic lock. The implementation method of InnoDB is:
- Transactions modify original data in the form of exclusive locks.
- Store the data before modification in the undo log, and associate it with the main data through the rollback pointer.
- If the modification is successful (commit), do nothing; if it fails, restore the data in the undo log (rollback).
The most essential difference between the two is whether to exclusively lock when modifying data, and whether it is still MVCC if locked.
MVCC can ensure that consistent data can be read without blocking. However, the MVCC theory does not restrict the implementation details, so different databases have different semantics. For example:
- PostgreSQL also uses optimistic concurrency control for write operations; it saves multiple different versions of the same row of data records in the table, and each write operation is a creation rather than an update; when a transaction is committed, it checks whether the data submitted by the current transaction has a write conflict according to the version number, and if so, throws an exception to inform the user and rolls back the transaction.
- InnoDB only has no locks for reads, and write operations still use pessimistic concurrency control with locks. This means that in InnoDB, you can only see rollbacks due to deadlocks and immutability constraints, but not rollbacks due to write conflicts. Unlike PostgreSQL, which creates new records in the table for data modifications, InnoDB retains only one copy of each row of data in the table. When updating data, it locks the row and writes the old version of the data to the undo log. Both the table and the row data in the undo log record the transaction ID, and when retrieving, the row data is read according to the transaction isolation level. It can be seen that write operations in MVCC can still be implemented according to pessimistic concurrency control.
MVCC solves the problem that reads and writes do not block each other. Each update generates a new version, and reads can read historical versions. Imagine that if a piece of data has only one version, do multiple transactions need read-write locks to protect this data when reading and writing?
An implementation where a read-write transaction adds a read/write lock before accessing data during operation is called a pessimistic lock. Pessimism is reflected in locking first, monopolizing data, and preventing others from locking.
What about optimistic locks? For read-write transactions, before the actual commit, no read/write lock is added, but the version/timestamp of the data is checked first. When it is time to actually commit, check the version/timestamp again. If the two are the same, it means that no one else has modified the data during this period, and then it can be safely committed.
Optimism is reflected in not locking in advance when accessing data. In situations where resource conflicts are not intense, using optimistic locks has better performance.
If resource conflicts are serious, the implementation of optimistic locks will cause transactions to often see that others have modified the data before them when committing, and then need to roll back or retry, which is not as good as locking at the beginning.
4. Snapshot Read and Current Read
Snapshot read means that when reading data, it will read the transaction-visible version of the data (which may be expired data) according to certain rules without locking.
Current read reads the latest version and locks the read record to ensure that other transactions will not modify this record concurrently to avoid security issues. Scenarios using current read:
- select…lock in share mode (shared read lock)
- select…for update
- update
- delete
- insert
Scenarios using snapshot read:
- Simple select operations, excluding the above select … lock in share mode and select … for update.
Let’s understand snapshot read and current read with an example: Under the RR isolation level of MySQL InnoDB, suppose you have opened two transactions, A and B. There is a user table with four pieces of data.
CREATE TABLE user (id int(11) NOT NULL,name varchar(64) NOT NULL,PRIMARY KEY (id),KEY name (name) )ENGINE=InnoDB;insert into user values(0,"Jack"),(5,"Tom"), (10,"Jerry"),(15,"ZhangSan");When you execute select *, both transactions A and B will return the same 4 pieces of data. It goes without saying that under the RR isolation level, when performing a normal select query, InnoDB will execute a snapshot read by default, which is equivalent to taking a photo of your current state. When you execute select later, it will return the data in this current photo. Even if other transactions are committed, it will not affect you. This realizes repeatable read. When is this photo generated?
It is not when the transaction is started, but when you execute select for the first time. That is to say, when A starts a transaction and does not perform any operations, and then B inserts a piece of data and commits, then when A executes select in the transaction, it can see the data added by B in its own transaction… After that, no matter if other transactions are committed, it doesn’t matter because the photo has been generated and will not be generated again. It will refer to this photo in the future.
Summary
The so-called MVCC (Multi-Version Concurrency Control) refers to the process in which transactions using the two isolation levels of Read Committed and Repeatable Read access the version chain of records when performing ordinary SELECT operations. This allows read-write and write-read operations of different transactions to be executed concurrently, thereby improving system performance.
A major difference between these two isolation levels is the timing of generating ReadView. Read Committed generates a ReadView before each ordinary SELECT operation, while Repeatable Read generates a ReadView only before the first ordinary SELECT operation. The repeatable read of data is actually the reuse of ReadView.
InnoDB implements MVCC by adding two additional hidden values to each row of records. One records when this row of data was created, and the other records when this row of data expires (or is deleted). However, InnoDB does not store the actual time when these events occur; instead, it only stores the system version number when these events occur. This is a number that keeps increasing as transactions are created. Each transaction records its own system version number at the start of the transaction. Each query must check whether the version number of each row of data is the same as the version number of the transaction.
The result of this additional record is that most queries do not need to acquire a lock at all.
They simply read data as quickly as possible, ensuring that only eligible rows are selected. The disadvantage of this scheme is that the storage engine must store more data for each row, do more checking work, and handle more aftercare operations.
The main advantage of using MVCC (Multi-Version Concurrency Control) over the locking model is that in MVCC, the lock requirements for retrieving (reading) data do not conflict with the lock requirements for writing data, so reads do not block writes, and writes never block reads.
There are also table-level and row-level locking mechanisms in the database for applications that cannot easily accept MVCC behavior. However, proper use of MVCC will always provide better performance than locks.
5. Thoughts
First, here is some basic knowledge of MySQL, let’s review it briefly.
5.1 MySQL’s default isolation level
MySQL’s isolation levels are: Read Uncommitted, Read Committed, Repeatable Read, and Serializable.
MySQL’s default isolation level is Repeatable Read, which can solve phantom reads.
What is a phantom read? Simply understood, it is that the results of two query operations in a transaction are different.
5.2 What locks do MySQL add for CRUD operations?
Query operations are not locked by default, but you can add an exclusive lock through for update, and a shared lock through lock in share mode.
Insert, update, and delete operations are by default exclusive locks.