1. Why Use Distributed Locks
When developing applications, if we need to access a shared variable synchronously in a multi-threaded environment, we can use Java’s multi-threaded techniques, which can run perfectly without bugs!
Note that this applies to standalone applications, where all requests are processed within the JVM of the current server and mapped to OS threads. The shared variable exists only in the memory space of this single JVM.
As business scales, applications evolve into distributed clusters with load balancing (as shown in the diagram). In this case:
- Variable A exists in the memory of three JVMs (JVM1, JVM2, JVM3). It typically appears as a member variable in a class (e.g., an integer in UserController).
- Without control, concurrent operations on Variable A across JVMs will produce incorrect results. Even with non-concurrent requests, the isolation of JVM memory spaces breaks data consistency.
To solve this, we need a cross-JVM mutual exclusion mechanism to control access to shared resources. This is the problem distributed locks address!
2. Implementation Methods of Distributed Locks
2.1 Database-based Implementation
- Solution: Design an independent table to store lock information. Acquire locks by inserting records and release them by updating/deleting records after business execution.
- Design and Implementation:
- Scheme 1
| Column Name | Type | Description |
| id | bigint | Primary key |
| method_name | varchar(64) | Method name (with a unique index) |
| desc | varchar(1024) | Remarks |
| update_time | datetime | Update time |
| out_date_time | datetime | Expiration time |
- Principle:
- Acquire lock: Insert a record into the table to mark lock ownership.
- Release lock: Delete the corresponding record to release the lock.
- Scheme 2
| Column Name | Type | Description |
| id | bigint | Primary key |
| method_name | varchar(64) | Method name (with a unique index) |
| desc | varchar(1024) | Remarks |
| update_time | datetime | Update time |
| version | int | Version number |
| state | int | State: 0 (unallocated), 1 (allocated) |
| out_date_time | datetime | Expiration time |
- Principle:
- Acquire lock:
- If no record exists, insert a new one with state=1 and version=1.
- If a record exists, check if it is unallocated (state=0). If so, update state to 1.
- Release lock: Update state to 0.
- Problems:
- Database downtime risk (requires master-slave replication?).
- Low concurrency and redundant lock information.
2.2 Redis-based Implementation
2.2.1 Basic Redis Implementation
- Key Commands:
- setNX (SET if Not eXists): Set a key-value pair only if the key does not exist.
- GETSET key value: Set a key’s value and return its old value.
- GET key: Retrieve a key’s value.
- EXPIRE key seconds: Set a timeout for automatic key deletion.
- Implementation:
- Locking:
Use setNX to store lock information, where the key is the lock name and the value is a UUID/requestID. After setNX succeeds, set an expiration time to enable automatic release.
- Unlocking:
- Automatic release after timeout.
- Manual release: Delete the key via DEL after business execution.
- Problems:
- setNX and EXPIRE are not atomic. A crash after setNX can cause deadlocks (workaround: set the lock value to its expiration time and use GETSET to reset expired locks).
- Single-point risk in Redis. With master-slave clusters, if the master fails before syncing the lock to the slave, the new master will lack the lock, causing concurrency issues (due to Redis being an AP model).
2.2.2 Using Redisson for Distributed Locks
- Principle: Redisson encapsulates Redis-based locks for easier use.
- Redisson Lock Types:
- Reentrant Lock
- Fair Lock
- MultiLock
- Red Lock
- ReadWriteLock
- Implementation:
- Locking:
Obtain an RLock object via RedissonClient, then use:
void lock(Long leaseTime, TimeUnit unit);
boolean tryLock(Long waitTime, Long leaseTime, TimeUnit unit);
- Unlocking:
Use RLock.unlock().
- Problems:
- Heavier dependency on additional components compared to basic Redis locks.
- Data inconsistency risks persist due to Redis’s AP model.
2.3 ZooKeeper-based Implementation
- ZooKeeper Node Types:
- Persistent Node (PERSISTENT)
- Persistent Sequential Node (PERSISTENT_SEQUENTIAL)
- Ephemeral Node (EPHEMERAL)
- Ephemeral Sequential Node (EPHEMERAL_SEQUENTIAL)
- Implementation Principle:
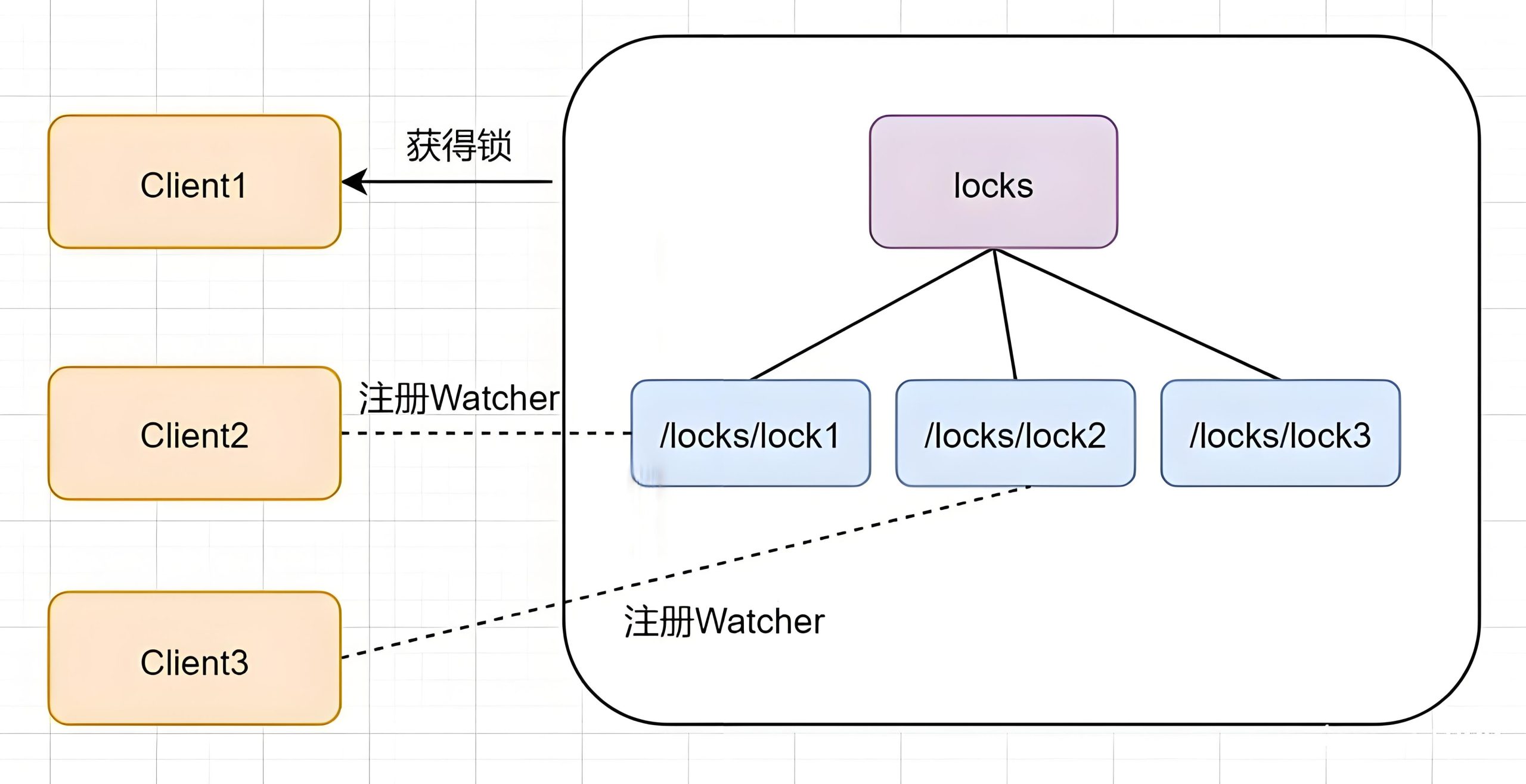
- Acquire Lock:
- Create a persistent node ParentLock.
- Clients create ephemeral sequential nodes (e.g., Lock1, Lock2) under ParentLock.
- A client checks if its node is the smallest in the sorted list of nodes under ParentLock. If yes, it acquires the lock.
- If not, the client registers a watcher on the preceding node (e.g., Lock2 watches Lock1) and waits.
- Release Lock:
- Explicit release: The client deletes its node after task completion.
- Implicit release: If the client crashes, its ephemeral node is automatically deleted (due to ZooKeeper’s session mechanism).
- When a node is deleted, the watching client checks if its node is now the smallest and acquires the lock.
- Problems:
- Low write concurrency (ZooKeeper requires majority node acknowledgment for writes).
- Lower read concurrency compared to Redis locks.