Hash Function
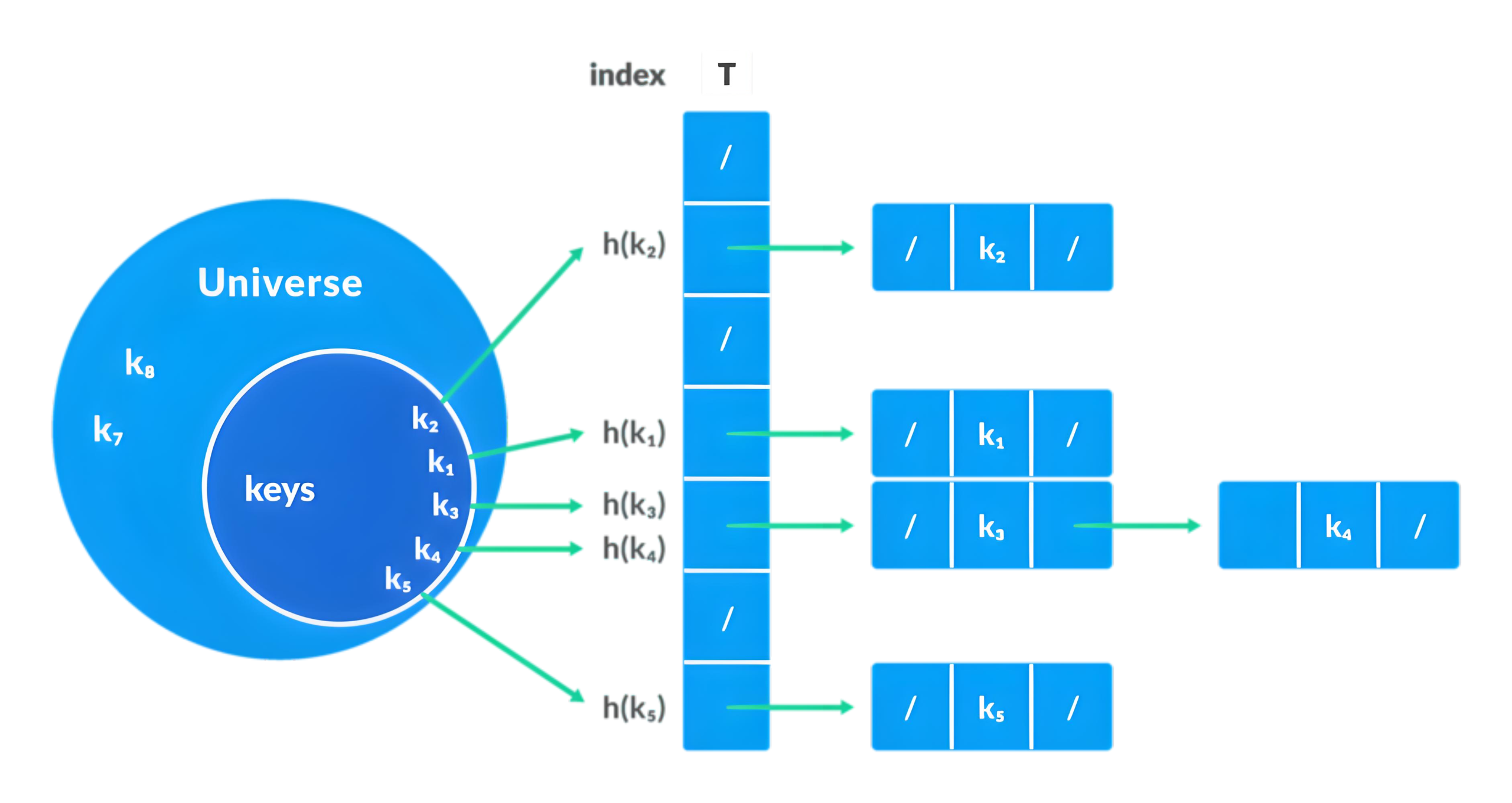
A hash function,is a function that maps data of arbitrary length to a fixed-length hash value. It can convert input data into a fixed-length string composed of numbers or letters, which usually serves as a fingerprint or digest of the data. Hash functions are widely used in data structures (such as hash tables) and cryptography, and the quality of their design directly affects the data distribution and performance of hash tables.
Designing a good hash function needs to consider the following aspects:
- Determinism: The same input must produce the same output. This means that if the input data remains unchanged, the output of the hash function must also be consistent.
- Efficiency: The speed of calculating hash values should be fast to ensure that a large number of hash operations can be completed quickly in practical applications.
- Uniformity: A good hash function can make the input data evenly distributed in the hash value space to reduce collisions. This means that for any key in the key set, the probability of being mapped to any address in the address set through the hash function is equal.
- Collision Resistance: The probability that different inputs (especially similar inputs) produce the same output should be as low as possible. Ideally, a hash function should try to avoid mapping different inputs to the same hash value (i.e., collision).
- Security: In specific application scenarios, such as password storage, the hash function needs to be one-way, that is, the original data cannot be derived from the hash value.
Common methods for constructing hash functions include direct addressing, division-remainder method, digit analysis, mid-square method, folding method, and random number method. Each of these methods has its advantages and disadvantages, and the choice of a suitable hash function depends on specific application scenarios and requirements.
For example, the direct addressing method is suitable for data where the key is of integer type, and the hash address is obtained through simple linear calculation. The division-remainder method, on the other hand, uses the remainder of the key divided by a number not greater than the length of the hash table as the hash address.
Designing an excellent hash function requires balancing these characteristics and adjusting according to the needs of practical applications. This not only helps improve data processing efficiency but also ensures data security and integrity to a certain extent.
What are the applications of hash functions in cryptography?
Hash functions are widely used in cryptography, mainly including the following aspects:
- Data Integrity Verification: By comparing the hash values of data, it can be ensured that the data has not been tampered with during transmission. For example, in blockchain technology, the cryptographic hash of each block depends on the cryptographic hash value of the previous block. Changing a block will cause the hash values of subsequent blocks to be recalculated, thereby forming the “chain” of the blockchain and ensuring the authenticity and integrity of the data.
- Digital Signature: Hash functions are used to generate message digests, which serve as the object of signatures to improve the efficiency of signing. A digital signature is generated by encrypting the message digest with a private key to produce digital signature data. The sender encrypts the data with a public key, and the receiver decrypts it with a private key and verifies the data source.
- Cryptographic Protocols: Used to generate session keys and identity verification codes to ensure the security of communication. For example, in some protocols, hash functions can be used to generate one-time passwords or verification codes to ensure the security of communication.
- Hash Cash: Used to implement decentralized network currency systems, such as Bitcoin. The SHA-256 algorithm used in Bitcoin has the characteristics of collision resistance, hiding, and puzzle creation, which make it very useful in scenarios such as mining.
- Message Authentication: Implement message authentication by encrypting the hash value or using only the hash value. Message Authentication Code (MAC) is a message authentication code based on a symmetric key, used to verify the integrity and authenticity of messages.
- Secure Hash Algorithms: Such as MD5 and SHA series algorithms, used to store and compare passwords to prevent internal employees from leaking all users’ password data. When the user enters the password again, the server performs hash comparison again to ensure the correctness of the password.
- Hash Tree (Merkle Tree): Used to efficiently and securely verify the content of large data structures. Transactions in a Bitcoin block are organized in the Merkle Tree format, corresponding to the hashMerkleTreeRoot in the block header, ensuring the immutability of transaction information.
How to quantify and evaluate the uniformity and collision resistance of hash functions?
Quantifying and evaluating the uniformity and collision resistance of hash functions is a key step to ensure their efficient operation in data processing. Here are several main methods:
- Uniformity Evaluation:
- Uniform Distribution Test: Use statistical methods such as the chi-squared test to evaluate whether the output of the hash function is uniformly distributed. This method can detect whether the hash values are evenly distributed in the output space.
- Bit Bias Analysis: Check whether the distribution of high and low bits in the random bit sequence generated by the hash function is close to 50% to 50% to judge its uniformity.
- Avalanche Effect Test: Observe whether a change in one bit of the input leads to a change in approximately half of the bits in the output, which is one of the important indicators to measure the performance of the hash function.
- Collision Resistance Evaluation:
- Collision Rate Analysis: Use mathematical tools such as Poisson distribution to analyze the collision rates of different hash functions on different data sets, thereby evaluating their collision resistance.
- Collision Resolution Strategies: Evaluate the effectiveness of collision resolution mechanisms adopted by hash functions, such as open addressing and chaining, which can reduce or avoid hash collisions.
- Load Factor: Consider the load factor of the hash table (the number of elements filled in the table / the length of the hash table). A higher load factor may increase the possibility of collisions, so it needs to be controlled reasonably.
- Comprehensive Performance Evaluation:
- Computational Efficiency: Evaluate the calculation speed and complexity of the hash function to ensure its efficiency in large-scale data processing.
- Determinism and Simplicity: Ensure that the same input always produces the same hash value, and the hash function itself is designed simply, easy to understand and implement.
What are the advantages and disadvantages of direct addressing, division-remainder method, digit analysis, mid-square method, folding method, and random number method?
Direct addressing, division-remainder method, digit analysis, mid-square method, folding method, and random number method each have their own advantages and disadvantages, which are analyzed in detail below:
Direct Addressing
Advantages:
- Simple calculation, no complex mathematical operations required.
- No hash collisions will occur because each key has a unique hash address.
Disadvantages:
- If the keys are unevenly distributed, it may lead to a lot of space waste.
- It is necessary to know the distribution of keys in advance, which may be difficult to achieve in practical applications.
Division-Remainder Method
Advantages:
- Simple calculation, only division and remainder operations are needed.
- Wide range of applications, suitable for hash tables of various sizes.
Disadvantages:
- Prone to hash collisions, especially when the keys are unevenly distributed.
- To reduce collisions, a prime number is usually chosen as the divisor, but this increases the complexity of calculation.
Digit Analysis
Advantages:
- Can hash according to different characteristics of keys, suitable for cases where the key has a large number of digits.
- High sensitivity, can better reflect the distribution characteristics of keys.
Disadvantages:
- Requires complex analysis and processing of keys, resulting in a large amount of calculation.
- For some specific data sets, it may not produce ideal hashing effects.
Mid-Square Method
Advantages:
- Expand the difference of keys through square operation, so that different keys generate different hash addresses.
- Suitable for cases where the key distribution is unknown and the number of digits is not very large.
Disadvantages:
- There is a periodic problem, and some seed values may cause the sequence to degenerate into a constant or zero.
- It is necessary to select an appropriate initial seed value to ensure randomness.
Folding Method
Advantages:
- No need to know the distribution of keys in advance, suitable for cases where the key has a large number of digits.
- Relatively simple calculation, only need to split the key into several parts and sum them.
Disadvantages:
- If the keys are unevenly distributed, it may lead to the concentration of hash addresses in certain positions.
- For very large keys, multiple foldings may be needed to get a reasonable hash address.
Random Number Method
Advantages:
- Can generate true random numbers based on true random events.
- Suitable for application scenarios that require high randomness.
Disadvantages:
- It is necessary to ensure the authenticity and randomness of random events; otherwise, the generated random numbers may not be ideal.
- The implementation is relatively complex and requires a high-quality random number generator.
How to balance determinism, efficiency, uniformity, collision resistance, and security when designing a hash function?
When designing a hash function, it is necessary to balance the five key characteristics of determinism, efficiency, uniformity, collision resistance, and security. The following is a detailed analysis:
- Determinism: A hash function must be deterministic, that is, for the same input, it always produces the same output. This is the basis for ensuring data consistency and predictability.
- Efficiency: The hash function should calculate the hash value as quickly as possible to improve performance. This means that during each interaction with data, the calculation process should be as simple as possible, avoiding complex mathematical operations such as multiplication and division. For example, methods such as additive hashing and XOR hashing can be used to achieve fast calculation.
- Uniformity: The hash function should be able to evenly distribute input data to various positions in the hash table, avoiding over-concentration in some positions and idleness in others. This can be achieved by using all key fields to calculate hash values, introducing randomness, etc. Uniform distribution helps reduce the occurrence of collisions, thereby improving data retrieval efficiency.
- Collision Resistance: The hash function should try to reduce the probability that different inputs generate the same hash value (i.e., collision). Although it is impossible to completely avoid collisions, a well-designed hash function can significantly reduce the collision rate. For example, using prime modulus can reduce collisions.
- Security: In the field of cryptography, hash functions need higher security features, including one-wayness, collision resistance, and avalanche effect. One-wayness means that no information about the input data can be derived from the hash value; collision resistance requires that it is extremely difficult to find two different inputs such that their hash values are the same; the avalanche effect requires that a small change in the input should lead to a significant and unpredictable change in the output.
To balance these characteristics, the following strategies can be considered when designing a hash function:
- Using Multiple Algorithms: Combine different hash algorithms (such as MD5, SHA series) to meet the needs of different scenarios. MD5 is often used for data integrity verification, while the SHA series is used to ensure data integrity and security.
- Optimizing Conflict Handling: Adopt methods such as chaining or red-black trees to handle conflicts to improve search efficiency and performance.
- Considering a Wide Input Range: The designed hash function should be able to process various types of input data, and the generated hash values should be evenly distributed within the possible output range.
What are the efficient hash function design strategies for large datasets?
For large datasets, strategies for designing efficient hash functions can be considered from multiple aspects:
- Combination of Multiple Hash Functions: Using multiple independent hash functions can reduce the probability of hash collisions and improve the performance of Bloom filters. For example, when processing URL blacklists, mapping URLs to bitmaps through multiple hash functions can effectively reduce the false positive rate.
- Fast Hash Function Algorithms: Choose efficient and fast hash function algorithms such as MurmurHash or CityHash, which can improve calculation speed while ensuring hashing effects. CityHash is particularly suitable for processing a large number of strings and other types of data, with good distribution and low collision rate.
- Hash Function Precomputation: For fixed data sets or deterministic hash functions, hash results can be precomputed and saved to speed up calculations during queries. This method is very useful when processing the same key values repeatedly.
- Consistent Hashing: Used for the organization of data servers. By imagining the return domain of hash values as a ring, it realizes distributed storage of data and reduces data migration costs. Consistent hashing solves the problem of load imbalance in classic hash servers when adding or deleting machines.
- Using the Idea of Segmented Statistics: Divide the data range into multiple equal parts, use an integer array to count the word frequency for each part, and count the word frequency within the range in a cyclic manner. This method saves space and improves efficiency in large data processing.
- Bitmap and Segmented Statistics: Used to count the number of occurrences of numbers in a certain range, saving space. It is realized through hash function shunting, which can effectively solve the problem of searching large-scale data even with limited memory.
- Heap Sort and External Sort: For the processing of large files, a small root heap can be used to merge the results of multiple processing units, and ordered files can be output through sorting, realizing ordered file output. This method is suitable for cases with limited memory.
- Union-Find Set: Used to determine whether two elements belong to the same set and merge two sets. The initialization and optimization methods of the union-find set, such as flattened query and the average time complexity of O(1) for merging times, are very useful in large data processing.